HTTP相关内容
HTTP相关内容
HTTP基本概念
HTTP是超文本传输协议,也就是HyperText Transfer Protocol。
HTTP是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」。
那HTTP是用于从互联网服务器传输超文本到本地浏览器的协议,这种说法正确吗?
这种说法是不正确的。因为也可以是「服务器<–>服务器」﹐所以采用两点之间的描述会更准确。
HTTP报文的组成部分
在回答此问题时,我们要按照顺序回答:
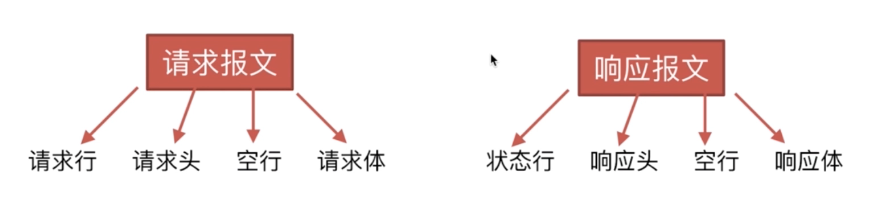
先回答的是,http报文包括:请求报文和响应报文。
再回答的是,每个报文包含什么部分。
最后回答,每个部分的内容是什么
请求报文包括:
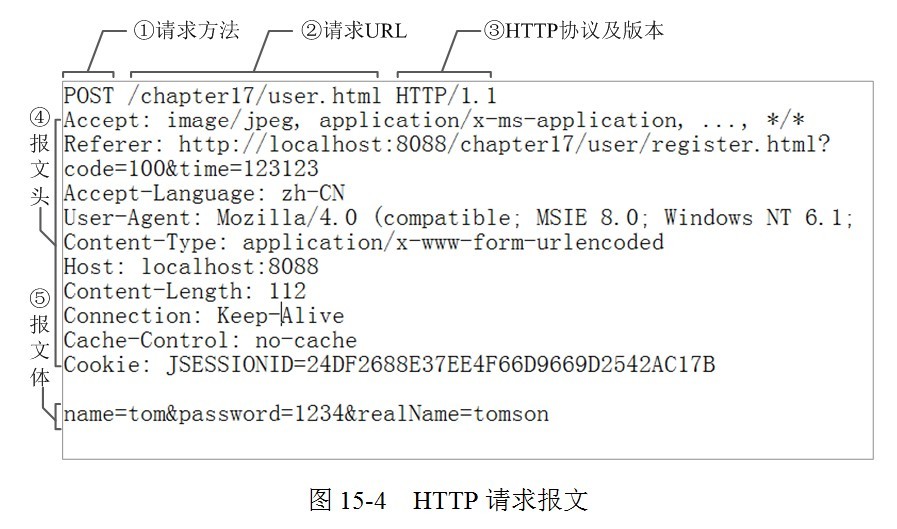
请求行:包括请求方法、请求的URL、HTTP协议及版本。
请求头:一大堆的键值对。
空行指的是:当服务器在解析请求头的时候,如果遇到了空行,则表明,后面的内容是请求体。
请求体:数据部分。
常见字段有哪些?
Host字段
客户端发送请求时,用来指定服务器的域名。
1 | Host: www .A.com |
有了Host字段,就可以将请求发往同一台服务器上的不同网站。
Content-Length 字段
浏览器报文中实体数据的大小
1 | Content-Length: 1000 |
Connection字段
Connection字段最常用于客户端要求服务器使用TCP持久连接,以便其他请求复用。
HTTP/1.1版本的默认连接都是持久连接,但为了兼容老版本的HTTP,需要指定Connection首部字段的值为Keep-Alive。
1 | Connection : Keep-Alive |
一个可以复用的TCP连接就建立了,直到客户端或服务器主动关闭连接。但是,这不是标准字段。
Content-Type字段
Content-Type字段用于服务器回应时,告诉客户端,本次数据是什么格式
1 | Content-Type: text/html; charset=utf-8 |
上面的类型表明,发送的是网页,而且编码是UTF-8。
客户端请求的时候,可以使用Accept字段声明自己可以接受哪些数据格式
1 | Accept: */* |
上面代码中,客户端声明自己可以接受任何格式的数据。
Content-Encoding字段
Content-Encoding 字段说明数据的压缩方法。表示服务器返回的数据使用了什么压缩格式
1 | Content-Encoding : gzip |
上面表示服务器返回的数据采用了gzip方式压缩,告知客户端需要用此方式解压。
客户端在请求时,用Accept-Encoding字段说明自己可以接受哪些压缩方法。
1 | Accept-Encoding: gzip, deflate |
响应报文包括:

- 状态行:HTTP协议及版本、状态码及状态描述。
- 响应头
- 空行
- 响应体
HTTP状态码

1xx
1xx类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。
2xx
2xx类状态码表示服务器成功处理了客户端的请求,也是我们最愿意看到的状态。
- 200 OK 是最常见的成功状态码,表示一切正常。如果是非
HEAD请求,服务器返回的响应头都会有body数据。 - 204 No Content 也是常见的成功状态码,与200 OK基本相同,但响应头没有body数据。
- **206 Partial Content **是应用于HTTP分块下载或断点续传,表示响应返回的body数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态。
3xx
3xx类状态码表示客户端请求的资源发送了变动,需要客户端用新的URL重新发送请求获取资源,也就是重定向。
301 Moved Permanently 表示永久重定向,说明请求的资源已经不存在了,需改用新的URL再次访问。
302 Found 表示临时重定向,说明请求的资源还在,但暂时需要用另一个URL来访问。
- 301和302都会在响应头里使用字段Location,指明后续要跳转的URL,浏览器会自动重定向新的URL。
304 Not Modified 不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,用于缓存控制。
4xx
4xx类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 400 Bad Request 表示客户端请求的报文有错误,但只是个笼统的错误
- 403 Forbidden 表示服务器禁止访问资源,并不是客户端的请求出错。
- 404 Not Found 表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx
5xx类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
- 500 Internal Server Error 与400类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
- 501 Not lmplemented 表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
- 502 Bad Gateway 通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
- 503 Service Unavailable 表示服务器当前很忙,暂时无法响应服务器,类似“网络服务正忙,请稍后重试”的意思。
HTTP方法
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD 方法。
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
根据场景合理使用各个方法,可以起到优化性能、增加网络安全的效果。
GET 与 POST
简要概述
GET方法的含义是请求从服务器获取资源,这个资源可以是静态的文本、页面、图片视频等。
比如,你打开我的文章,浏览器就会发送GET请求给服务器,服务器就会返回文章的所有文字及资源。
而POST方法则是相反操作,它向URI指定的资源提交数据,数据就放在报文的body里。
比如,你在我文章底部,敲入了留言后点击「提交」,浏览器就会执行一次POST请求,把你的留言文字放进了报文body里,然后拼接好POST请求头,通过TCP协议发送给服务器。
安全和幂等
先说明下安全和幂等的概念:
- 在HTTP 协议里,所谓的「安全」是指请求方法不会「破坏」服务器上的资源。
- 所谓的「幂等」,意思是多次执行相同的操作,结果都是「相同」的。
那么很明显GET方法就是安全且幂等的,因为它是「只读」操作,无论操作多少次,服务器上的数据都是安全的,且每次的结果都是相同的。
POST因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以不是幂等的。
参数传递方式
这一点应该是我们能够最直观地观察到的。
- GET 的参数一般是通过
?跟在 URL 后面的,多个参数通过&连接,比如:www.example.com?serach=bianchengsanmei&content=123。 - POST 的参数一般是包含在
request body中的
其实,这个区别不是绝对的,GET 也可以通过 params 携带参数,而 POST 的URL 后面也可以携带参数,只是我们通常不建议这么做而已。
安全性不同(传输的角度)
因为参数传递方式的不同,所以 GET 和 POST 的安全性不同:GET 比 POST 更不安全,因为参数直接暴露在URL上,所以 GET 不能用来传递敏感信息。
从传输的角度来说,他们都是不安全的,因为 HTTP 在网络上是明文传输的,只要在网络节点上捉包,就能完整地获取数据报文,要想安全传输,就只有加密,也就是 HTTPS。
参数长度限制不同
GET 和 POST 传递参数的长度不同:
- get传送的数据量较小,不能大于2KB。
- post传送的数据量较大,一般被默认为不受限制。
在这里我们要明确一点:HTTP 协议没有 Body 和 URL 的长度限制,对 URL 限制的大多是浏览器和服务器的原因。
服务器是因为处理长 URL 要消耗比较多的资源,为了性能和安全(防止恶意构造长 URL 来攻击)考虑,会给 URL 长度加限制。
参数数据类型不同
参数的数据类型,GET 只接受 ASCII 字符,而 POST 没有限制。
编码方式不同
GET 请求只能进行 URL 编码(application/x-www-form-urlencoded)
POST 支持多种编码方式(application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多种编码。)
缓存机制不同
这个需要从以下几点来说明:
- GET 请求会被浏览器主动cache,而 POST 不会,除非手动设置。
- GET 请求参数会被完整保留在浏览器历史记录里,而 POST 中的参数不会被保留。
- GET 产生的 URL 地址可以被 Bookmark,而 POST 不可以。
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求。
时间消耗不同
GET 和 POST 请求时间的不同主要是因为:
- GET 产生一个 TCP 数据包;
- POST 产生两个 TCP 数据包。
对于 GET 方式的请求,浏览器会把 header 和 data 一并发送出去,服务器响应 200(返回数据);而对于 POST,浏览器先发送 header,服务器响应 100 continue,浏览器再发送 data,服务器响应 200 ok(返回数据),详细分析一下:
POST 请求的过程:
- 浏览器请求 TCP 连接(第一次握手)
- 服务器答应进行 TCP 连接(第二次握手)
- 浏览器确认,并发送 POST 请求头(第三次握手,这个报文比较小,所以 HTTP 会在此时进行第一次数据发送)
- 服务器返回100 Continue响应
- 浏览器发送数据
- 服务器返回 200 OK响应
GET 请求的过程:
- 浏览器请求 TCP 连接(第一次握手)
- 服务器答应进行 TCP 连接(第二次握手)
- 浏览器确认,并发送 GET 请求头和数据(第三次握手,这个报文比较小,所以 HTTP 会在此时进行第一次数据发送)
- 服务器返回 200 OK响应
在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
HEAD
与 GET 方法一样,都是向服务器发出指定资源的请求,只不过服务器将不传回资源的本文部分,只返回头部消息。
HEAD 方法的使用场景
- 在不获取资源的情况下,了解资源的一些信息,比如资源类型;
- 通过查看响应中的状态码,可以确定资源是否存在;
- 通过查看首部,测试资源是否被修改。
PUT
PUT 方法用于将数据发送到服务器来创建/更新资源。
PUT 与 POST 方法的区别在于,PUT 方法是幂等的:调用一次与连续调用多次是等价的(即没有副作用),而连续调用多次 POST 方法可能会有副作用,比如将一个订单重复提交多次。
DELETE
DELETE 方法就是请求服务器删除指定 URL 所对应的资源。
但是,客户端无法保证删除操作一定会被执行,因为 HTTP 规范允许服务器在不通知客户端的情况下撤销请求。
TRACE
TRACE 方法实现沿通向目标资源的路径的消息“回环”(loop-back)测试 ,提供了一种实用的 debug 机制。
请求的最终接收者应当原样反射(reflect)它接收到的消息,作为一个 Content-Type 为 message/http 的200(OK)响应的消息的主体(body)返回给客户端 。
最终接收者是指初始(origin)服务器,或者第一个接收到 Max-Forwards 值为 0的请求的服务器。
我们都知道,客户端在发起一个请求时,这个请求可能要穿过防火墙、代理、网关、或者其它的一些应用程序。这中间的每个节点都可能会修改原始的 HTTP 请求。由于有一个“回环”诊断,在请求最终到达服务器时,服务器会弹回一条 TRACE 响应,并在响应主体中携带它收到的原始请求报文的最终模样。这样客户端就可以查看 HTTP 请求报文在发送的途中,是否被修改过了。
PATCH
在HTTP协议中,请求方法 PATCH 用于对资源进行部分修改。
在HTTP协议中, PUT 方法已经被用来表示对资源进行整体覆盖, 而 POST 方法则没有对标准的补丁格式的提供支持。不同于 PUT 方法,而与 POST 方法类似,PATCH 方法是非幂等的,这就意味着连续多个的相同请求会产生不同的效果。
要判断一台服务器是否支持 PATCH 方法,那么就看它是否将其添加到了响应首部 Allow 或者 Access-Control-Allow-Methods (在跨域访问的场合,CORS)的方法列表中 。
另外一个支持 PATCH 方法的隐含迹象是 Accept-Patch 首部的出现,这个首部明确了服务器端可以接受的补丁文件的格式。
OPTIONS
OPTIONS 方法用于获取目的资源所支持的通信选项。
客户端可以对特定的 URL 使用 OPTIONS 方法,也可以对整站(通过将 URL 设置为“*”)使用该方法。
若请求成功,则它会在 HTTP 头中包含一个名为 “Allow” 的头,值是所支持的方法,如 “GET, POST”。
CONNECT
CONNECT 方法可以开启一个客户端与所请求资源之间的双向沟通的通道。它可以用来创建隧道(tunnel)。
HTTP特性
优点
HTTP最凸出的优点是简单、灵活和易于扩展、应用广泛和跨平台。
简单
HTTP基本的报文格式就是 header + body ,头部信息也是key-value简单文本的形式,易于理解,降低了学习和使用的门槛。
灵活和易于扩展
HTTP协议里的各类请求方法、URIURL、状态码、头字段等每个组成要求都没有被固定死,都允许开发人员自定义和扩充。
同时HTTP由于是工作在**应用层(OSI第七层)**,则它下层可以随意变化。
HTTPS也就是在HTTP与TCP层之间增加了SSLTLS安全传输层,HTTP/3甚至把TCP层换成了基于UDP的QUIC。
应用广泛和跨平台
互联网发展至今,HTTP的应用范围非常的广泛,从台式机的浏览器到手机上的各种 APP,从看新闻、刷贴吧到购物、理财、吃鸡,HTTP的应用片地开花,同时天然具有跨平台的优越性。
缺点
HTTP协议里有优缺点一体的双刃剑,分别是无状态、明文传输,同时还有一大缺点不安全。
无状态双刃剑
无状态的好处,因为服务器不会去记忆HTTP的状态,所以不需要额外的资源来记录状态信息,这能减轻服务器的负担,能够把更多的CPU和内存用来对外提供服务。
无状态的坏处,既然服务器没有记忆能力,它在完成有关联性的操作时会非常麻烦。
例如登录->添加购物车->下单->结算->支付,这系列操作都要知道用户的身份才行。但服务器不知道这些请求是有关联的,每次都要问一遍身份信息。
这样每操作一次,都要验证信息,这样的购物体验还能愉快吗?别问,问就是酸爽!
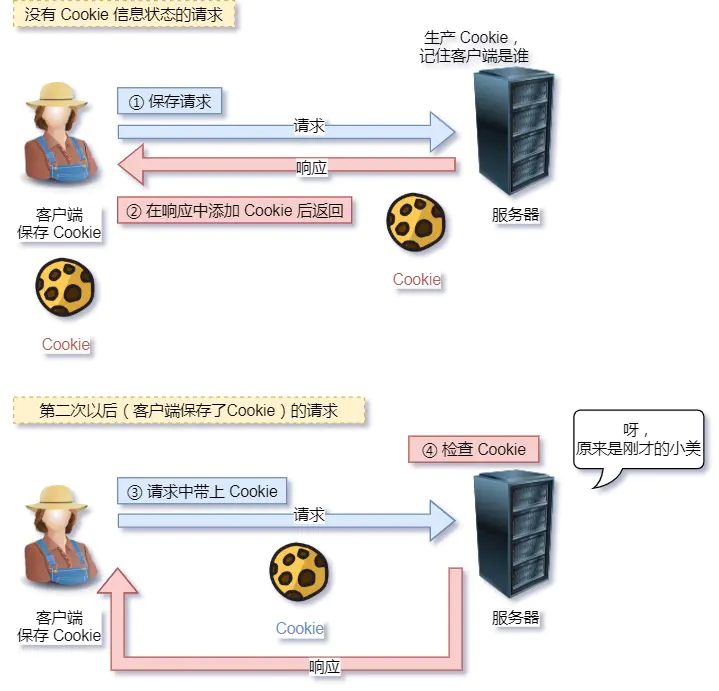
对于无状态的问题,解法方案有很多种,其中比较简单的方式用Cookie技术。
Cookie通过在请求和响应报文中写入Cookie 信息来控制客户端的状态。
相当于,在客户端第一次请求后,服务器会下发一个装有客户信息的「小贴纸」,后续客户端请求服务器的时候,带上「小贴纸」,服务器就能认得了。
明文传输双刃剑
明文意味着在传输过程中的信息,是可方便阅读的,通过浏览器的F12控制台或Wireshark抓包都可以直接肉眼查看,为我们调试工作带了极大的便利性。
但是这正是这样,HTTP的所有信息都暴露在了光天化日下,相当于信息裸奔。在传输的漫长的过程中,信息的内容都毫无隐私可言,很容易就能被窃取,如果里面有你的账号密码信息,那你号没了。
不安全
HTTP比较严重的缺点就是不安全:
- 通信使用明文(不加密),内容可能会被窃听。比如,账号信息容易泄漏,那你号没了。
- 不验证通信方的身份,因此有可能遭遇伪装。比如,访问假的淘宝、拼多多,那你钱没了。
- 无法证明报文的完整性,所以有可能已遭篡改。比如,网页上植入垃圾广告,视觉污染,眼没了。
HTTP的安全问题,可以用HTTPS的方式解决,也就是通过引入SSL/TLS层,使得在安全上达到了极致。
HTTP/1.1的性能
HTTP协议是基于TCP/IP,并且使用了「请求-应答」的通信模式,所以性能的关键就在这两点里。
长连接
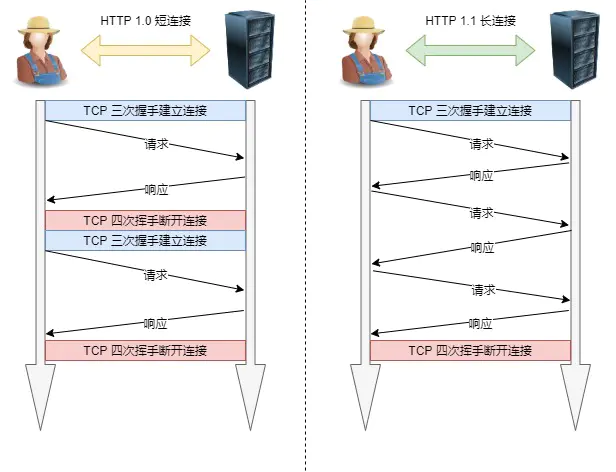
早期HTTP/1.0性能上的一个很大的问题,那就是每发起一个请求,都要新建一次TCP连接(三次握手),而且是串行请求,做了无谓的TCP连接建立和断开,增加了通信开销。
为了解决上述TCP连接问题,HTTP/1.1提出了长连接的通信方式,也叫持久连接。这种方式的好处在于减少了TCP连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。
持久连接的特点是,只要任意一端没有明确提出断开连接,则保持TCP连接状态。
管道网络传输
HTTP/1.1采用了长连接的方式,这使得管道(pipeline)网络传输成为了可能。
即可在同一个TCP连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个TCP连接里面,先发送A请求,然后等待服务器做出回应,收到后再发出B请求。管道机制则是允许浏览器同时发出A请求和B请求。
但是服务器还是按照顺序,先回应A请求,完成后再回应B请求。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为队头堵塞。
总之HTTP/1.1的性能一般般,后续的 HTTP/2和HTTP/3就是在优化HTTP的性能。
HTTP/1.1、HTTP/2、HTTP/3演变
HTTP/1.1
HTTP/1.1相比HTTP/1.0性能上的改进︰
- 使用TCP长连接的方式改善了HTTP/1.0短连接造成的性能开销。
- 支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
但HTTP/1.1还是有性能瓶颈︰
- 请求/响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩
Body的部分; - 发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
- 没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应。
HTTP/2
HTTP/2协议是大多基于HTTPS的,所以HTTP/2的安全性也是有保障的。
那HTTP/2相比HTTP/1.1 性能上的改进︰
头部压缩
HTTP/2会压缩头(Header)。如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。
这就是所谓的 HPACK算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
二进制格式
HTTP/2不再像HTTP/1.1里的纯文本形式的报文,而是全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧(frame)︰头信息帧和数据帧。
这样虽然对人不友好,但是对计算机非常友好,因为计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
数据流
HTTP/2的数据包不是按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。
每个请求或回应的所有数据包,称为一个数据流(Stream )。每个数据流都标记着一个独一无二的编号,其中规定客户端发出的数据流编号为奇数,服务器发出的数据流编号为偶数。
客户端还可以指定数据流的优先级。优先级高的请求,服务器就先响应该请求。
多路复用
HTTP/2是可以在一个连接中并发多个请求或回应,而不用按照顺序一一对应。
移除了HTTP/1.1中的串行请求,不需要排队等待,也就不会再出现「队头阻塞」问题,降低了延迟,大幅度提高了连接的利用率。
举例来说,在一个TCP连接里,服务器收到了客户端A和B的两个请求,如果发现A处理过程非常耗时,于是就回应A请求已经处理好的部分,接着回应B请求,完成后,再回应A请求剩下的部分。
服务器推送
HTTP/2还在一定程度上改善了传统的「请求-应答」工作模式,服务不再是被动地响应,也可以主动向客户端发送消息。
举例来说,在浏览器刚请求HTML的时候,就提前把可能会用到的JS、CSS 文件等静态资源主动发给客户端,减少延时的等待,也就是服务器推送(Server Push,也叫Cache Push)。
HTTP/3
HTTP/2主要的问题在于,多个HTTP请求在复用一个TCP连接,下层的TCP协议是不知道有多少个HTTP请求的。
所以一旦发生了丢包现象,就会触发TCP的重传机制,这样在一个TCP连接中的所有的HTTP请求都必须等待这个丢了的包被重传回来。
- HTTP/1.1中的管道( pipeline)传输中如果有一个请求阻塞了,那么队列后请求也统统被阻塞住了
- HTTP/2多个请求复用一个TCP连接,一旦发生丢包,就会阻塞住所有的HTTP请求
这都是基于TCP传输层的问题,所以HTTP/3把HTTP下层的TCP协议改成了UDP!
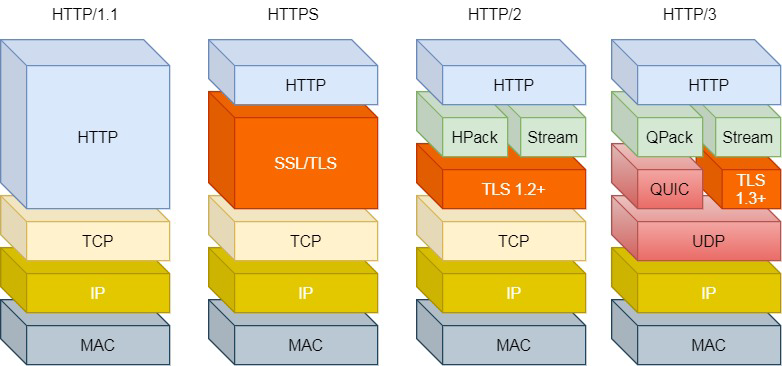
UDP是不管顺序,也不管丢包的,所以不会出现HTTP/1.1的队头阻塞和HTTP/2的一个丢包全部重传问题。
大家都知道UDP是不可靠传输的,但基于UDP的QUIC协议可以实现类似TCP的可靠性传输。
- QUIC有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响。
- TLS3升级成了最新的1.3版本,头部压缩算法也升级成了QPack 。
- HTTPS要建立一个连接,要花费6次交互,先是建立三次握手,然后是TLS/1.3的三次握手。QUIC直接把以往的TCP和 TLS/1.3的6次交互合并成了3次,减少了交互次数。
所以,QUIC是一个在UDP之上的伪TCP+ TLS+ HTTP/2的多路复用的协议。
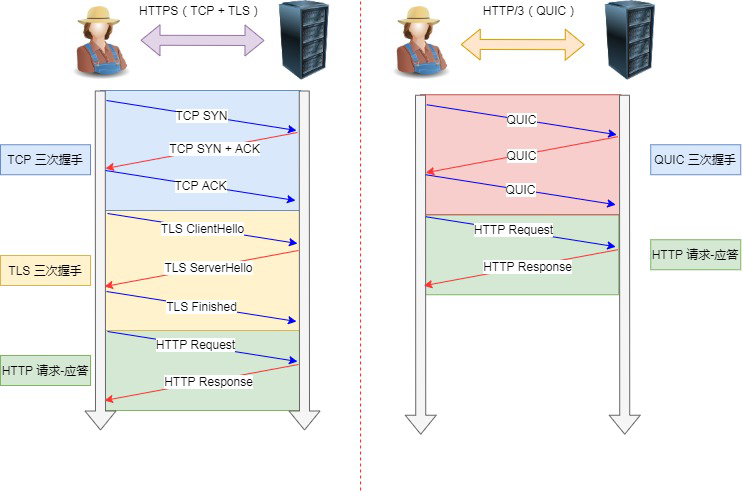
QUIC是新协议,对于很多网络设备,根本不知道什么是QUIC,只会当做UDP,这样会出现新的问题。所以HTTP/3现在普及的进度非常的缓慢,不知道未来UDP是否能够逆袭TCP。
HTTP和HTTPS
区别
- HTTP是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS则解决HTTP不安全的缺陷,在TCP和HTTP之间加入了SSL/TLS安全协议,使得报文能够加密传输。
- HTTP 连接建立相对简单,TCP三次握手之后便可进行HTTP的报文传输。而 HTTPS在TCP三次握手之后,还需进行SSL/TLS的握手过程,才可进入加密报文传输。
- HTTP的端口号是80,HTTPS的端口号是443。
- HTTPS 协议需要向CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
SSL和TLS?
这两实际上是一个东西。
SSL是洋文Secure Sockets Layer的缩写,中文叫做安全套接层。它是在上世纪90年代中期,由网景公司设计的。
到了1999年,SSL因为应用广泛,已经成为互联网上的事实标准。IETF就在那年把SSL标准化。
标准化之后的名称改为TLS(是Transport Layer Security的缩写),中文叫做传输层安全协议。
很多相关的文章都把这两者并列称呼(SSL/TLS),因为这两者可以视作同一个东西的不同阶段。
HTTP安全风险
HTTP由于是明文传输,所以安全上存在以下三个风险:
- 窃听风险,比如通信链路上可以获取通信内容,用户号容易没。
- 篡改风险,比如强制植入垃圾广告,视觉污染,用户眼容易瞎。
- 冒充风险,比如冒充淘宝网站,用户钱容易没。
HTTPS解决方案
HTTPS在HTTP与TCP层之间加入了 SSL/TLS 协议,可以很好的解决了上述的风险:
- 混合加密的方式实现信息的机密性,解决了窃听的风险。
- 摘要算法的方式来实现完整性,它能够为数据生成独一无二的「指纹」,指纹用于校验数据的完整性,解决了篡改的风险。
- 将服务器公钥放入到数字证书中,解决了冒充的风险。
混合加密
通过混合加密的方式可以保证信息的机密性,解决了窃听的风险。
HTTPS采用的是对称加密和非对称加密结合的「混合加密」方式:
- 在通信建立前采用非对称加密的方式交换「会话秘钥」,后续就不再使用非对称加密。
- 在通信过程中全部使用对称加密的「会话秘钥」的方式加密明文数据。
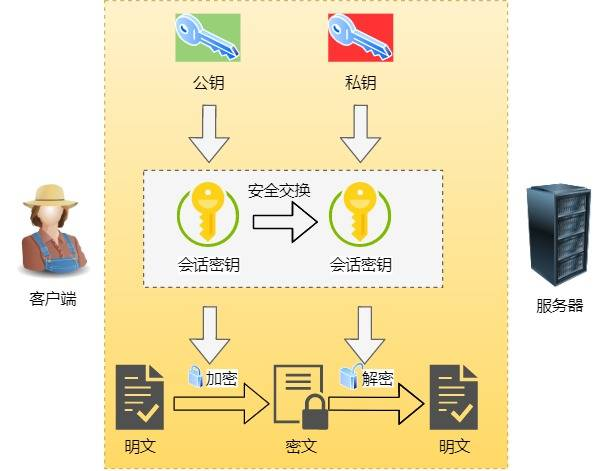
采用「混合加密」的方式的原因:
- 对称加密只使用一个密钥:运算速度快,密钥必须保密,无法做到安全的密钥交换。
- 非对称加密使用两个密钥:公钥和私钥,公钥可以任意分发而私钥保密,解决了密钥交换问题但速度慢。
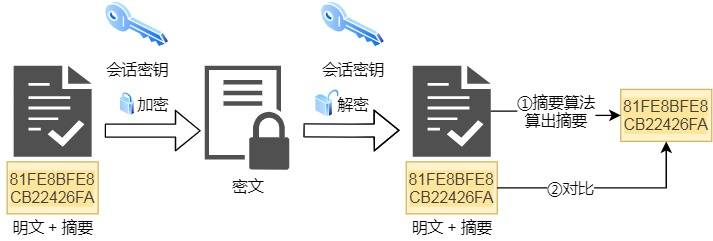
摘要算法
摘要算法用来实现完整性,能够为数据生成独一无二的指纹﹐用于校验数据的完整性,解决了篡改的风险。
客户端在发送明文之前会通过摘要算法算出明文的指纹,发送的时候把指纹+明文一同加密成密文后,发送给服务器,服务器解密后,用相同的摘要算法算出发送过来的明文,通过比较客户端携带的指纹和当前算出的指纹做比较,若指纹相同,说明数据是完整的。
数字证书
客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
这就存在些问题,如何保证公钥不被篡改和信任度?
所以这里就需要借助第三方权威机构CA(数字证书认证机构)﹐将服务器公钥放在数字证书(由数字证书认证机构颁发)中,只要证书是可信的,公钥就是可信的。
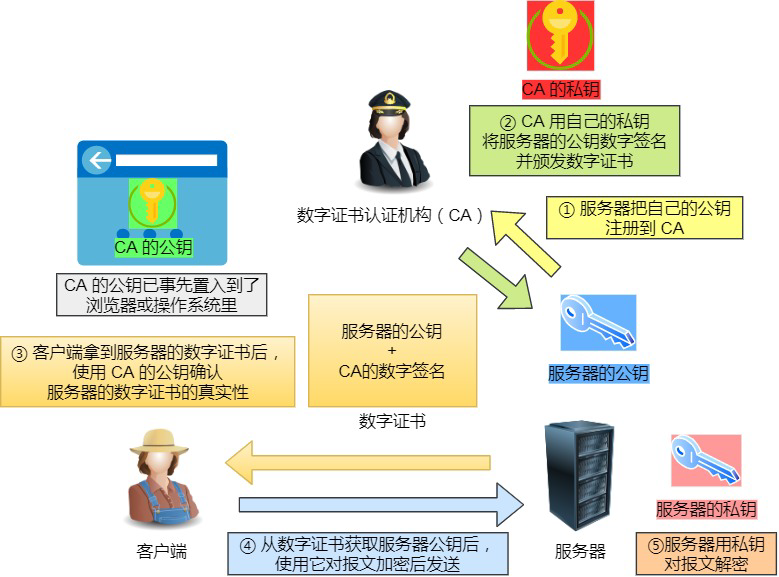
通过数字证书的方式保证服务器公钥的身份,解决冒充的风险。
HTTPS连接
SSL/TLS协议基本流程∶
- 客户端向服务器索要并验证服务器的公钥。
- 双方协商生产「会话秘钥」。
- 双方采用「会话秘钥」进行加密通信。
前两步也就是SSL/TLS的建立过程,也就是握手阶段。
SSL/TLS的「握手阶段」涉及四次通信,可见下图:
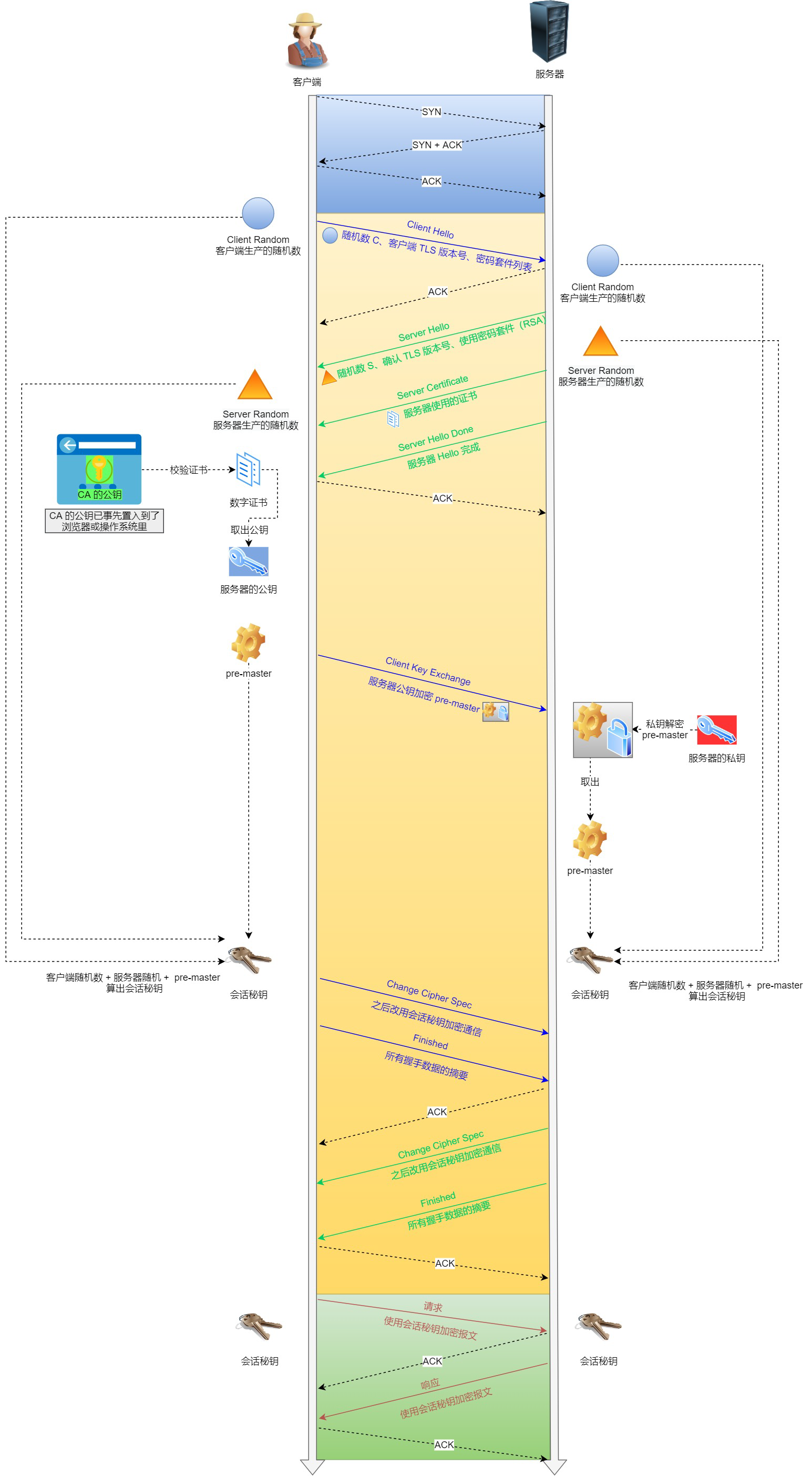
整个SSL/TLS的握手阶段全部结束后,客户端与服务器进入加密通信,就完全是使用普通的HTTP协议,只不过用「会话秘钥」加密内容。
SSL/TLS 1.2需要4次握手,需要2个RTT的时延,上图是把每个交互分开画了,实际上把他们合在一起发送,就是4次握手;
另外,SSL/TLS 1.3优化了过程,只需要1个RTT往返时延,也就是只需要3次握手。
HTTP 缓存
通过复用以前获取的资源,可以显著提高网站和应用程序的性能。Web 缓存减少了等待时间和网络流量,因此减少了显示资源表示形式所需的时间。通过使用 HTTP缓存,变得更加响应性。
不同种类的缓存
缓存是一种保存资源副本并在下次请求时直接使用该副本的技术。当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。这样带来的好处有:缓解服务器端压力,提升性能(获取资源的耗时更短了)。对于网站来说,缓存是达到高性能的重要组成部分。缓存需要合理配置,因为并不是所有资源都是永久不变的:重要的是对一个资源的缓存应截止到其下一次发生改变(即不能缓存过期的资源)。
缓存的种类有很多,其大致可归为两类:私有与共享缓存。共享缓存存储的响应能够被多个用户使用。私有缓存只能用于单独用户。本文将主要介绍浏览器与代理缓存,除此之外还有网关缓存、CDN、反向代理缓存和负载均衡器等部署在服务器上的缓存方式,为站点和 web 应用提供更好的稳定性、性能和扩展性。
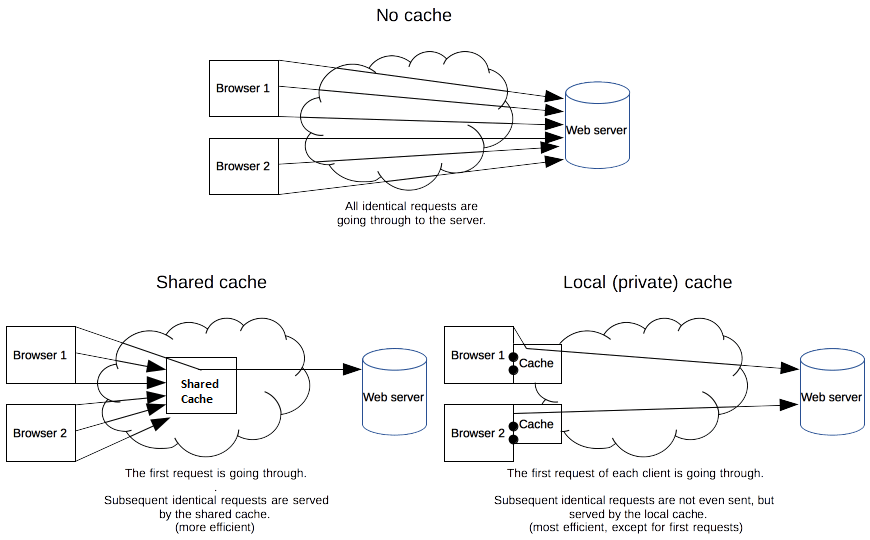
(私有)浏览器缓存
私有缓存只能用于单独用户。你可能已经见过浏览器设置中的“缓存”选项。浏览器缓存拥有用户通过 HTTP下载的所有文档。这些缓存为浏览过的文档提供向后/向前导航,保存网页,查看源码等功能,可以避免再次向服务器发起多余的请求。它同样可以提供缓存内容的离线浏览。
(共享)代理缓存
共享缓存可以被多个用户使用。例如,ISP 或你所在的公司可能会架设一个 web 代理来作为本地网络基础的一部分提供给用户。这样热门的资源就会被重复使用,减少网络拥堵与延迟。
缓存操作的目标
虽然 HTTP 缓存不是必须的,但重用缓存的资源通常是必要的。然而常见的HTTP 缓存只能存储 GET响应,对于其他类型的响应则无能为力。缓存的关键主要包括request method和目标URI(一般只有GET请求才会被缓存)。 普遍的缓存案例:
- 一个检索请求的成功响应: 对于
GET请求,响应状态码为:200,则表示为成功。一个包含例如HTML文档,图片,或者文件的响应。 - 永久重定向: 响应状态码:
301。 - 错误响应: 响应状态码:
404的一个页面。 - 不完全的响应: 响应状态码
206,只返回局部的信息。 - 除了
GET请求外,如果匹配到作为一个已被定义的cache键名的响应。
针对一些特定的请求,也可以通过关键字区分多个存储的不同响应以组成缓存的内容。
缓存控制
Cache-control 头
HTTP/1.1定义的 Cache-Control 头用来区分对缓存机制的支持情况, 请求头和响应头都支持这个属性。通过它提供的不同的值来定义缓存策略。
没有缓存
缓存中不得存储任何关于客户端请求和服务端响应的内容。每次由客户端发起的请求都会下载完整的响应内容。
1 | Cache-Control: no-store |
缓存但重新验证
如下头部定义,此方式下,每次有请求发出时,缓存会将此请求发到服务器(译者注:该请求应该会带有与本地缓存相关的验证字段),服务器端会验证请求中所描述的缓存是否过期,若未过期(注:实际就是返回304),则缓存才使用本地缓存副本。
1 | Cache-Control: no-cache |
私有和公共缓存
“public” 指令表示该响应可以被任何中间人(译者注:比如中间代理、CDN等)缓存。若指定了”public”,则一些通常不被中间人缓存的页面(译者注:因为默认是private)(比如 带有HTTP验证信息(帐号密码)的页面 或 某些特定状态码的页面),将会被其缓存。
而 “private” 则表示该响应是专用于某单个用户的,中间人不能缓存此响应,该响应只能应用于浏览器私有缓存中。
1 | Cache-Control: private |
过期
过期机制中,最重要的指令是 “max-age=<seconds>“,表示资源能够被缓存(保持新鲜)的最大时间。相对Expires而言,max-age是距离请求发起的时间的秒数。针对应用中那些不会改变的文件,通常可以手动设置一定的时长以保证缓存有效,例如图片、css、js等静态资源。
1 | Cache-Control: max-age=31536000 |
验证方式
当使用了 “must-revalidate“ 指令,那就意味着缓存在考虑使用一个陈旧的资源时,必须先验证它的状态,已过期的缓存将不被使用。
1 | Cache-Control: must-revalidate |
Pragma 头
Pragma是HTTP/1.0标准中定义的一个header属性,请求中包含Pragma的效果跟在头信息中定义Cache-Control: no-cache相同,但是HTTP的响应头没有明确定义这个属性,所以它不能拿来完全替代HTTP/1.1中定义的Cache-control头。通常定义Pragma以向后兼容基于HTTP/1.0的客户端。
新鲜度
理论上来讲,当一个资源被缓存存储后,该资源应该可以被永久存储在缓存中。由于缓存只有有限的空间用于存储资源副本,所以缓存会定期地将一些副本删除,这个过程叫做缓存驱逐。另一方面,当服务器上面的资源进行了更新,那么缓存中的对应资源也应该被更新,由于HTTP是C/S模式的协议,服务器更新一个资源时,不可能直接通知客户端更新缓存,所以双方必须为该资源约定一个过期时间,在该过期时间之前,该资源(缓存副本)就是新鲜的,当过了过期时间后,该资源(缓存副本)则变为陈旧的。驱逐算法用于将陈旧的资源(缓存副本)替换为新鲜的,注意,一个陈旧的资源(缓存副本)是不会直接被清除或忽略的,当客户端发起一个请求时,缓存检索到已有一个对应的陈旧资源(缓存副本),则缓存会先将此请求附加一个If-None-Match头,然后发给目标服务器,以此来检查该资源副本是否是依然还是算新鲜的,若服务器返回了 304 (Not Modified)(该响应不会有带有实体信息),则表示此资源副本是新鲜的,这样一来,可以节省一些带宽。若服务器通过 If-None-Match 或 If-Modified-Since判断后发现已过期,那么会带有该资源的实体内容返回。
下面是上述缓存处理过程的一个图示:
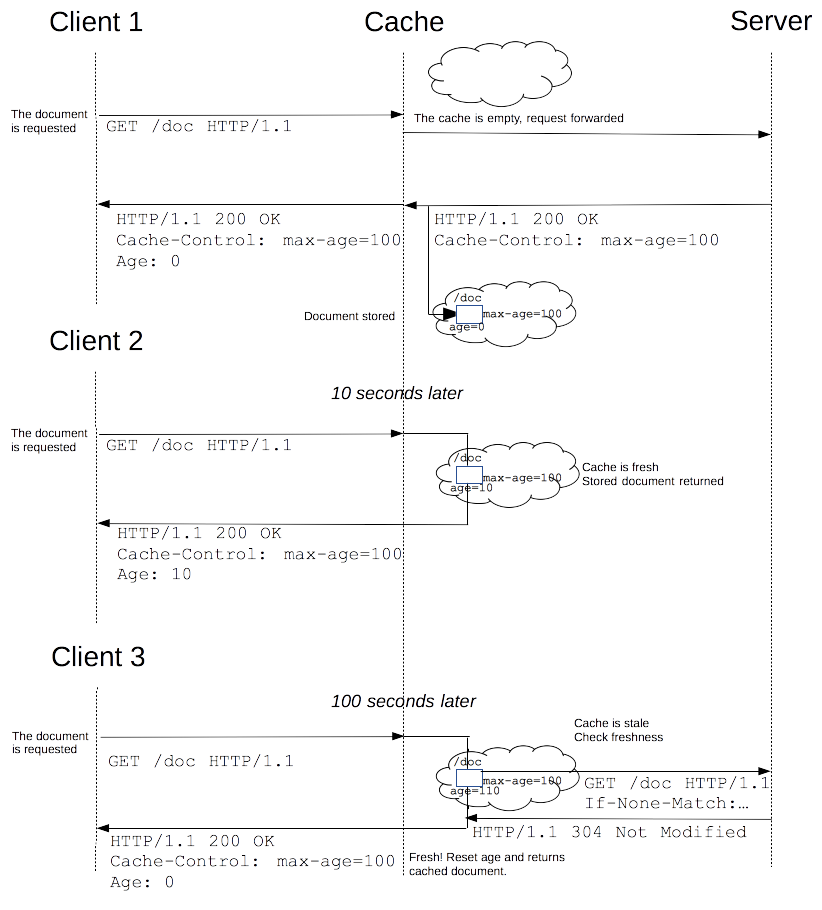
对于含有特定头信息的请求,会去计算缓存寿命。比如Cache-control: max-age=N的头,相应的缓存的寿命就是N。通常情况下,对于不含这个属性的请求则会去查看是否包含Expires属性,通过比较Expires的值和头里面Date属性的值来判断是否缓存还有效。如果max-age和expires属性都没有,找找头里的Last-Modified信息。如果有,缓存的寿命就等于头里面Date的值减去Last-Modified的值除以10(注:根据rfc2626其实也就是乘以10%)。
缓存失效时间计算公式如下:
1 | expirationTime = responseTime + freshnessLifetime - currentAge |
上式中,responseTime 表示浏览器接收到此响应的那个时间点。
缓存验证
用户点击刷新按钮时会开始缓存验证。如果缓存的响应头信息里含有”Cache-control: must-revalidate”的定义,在浏览的过程中也会触发缓存验证。另外,在浏览器偏好设置里设置Advanced->Cache为强制验证缓存也能达到相同的效果。
当缓存的文档过期后,需要进行缓存验证或者重新获取资源。只有在服务器返回强校验器或者弱校验器时才会进行验证。
ETags
作为缓存的一种强校验器,ETag响应头是一个对用户代理(User Agent, 下面简称UA)不透明(译者注:UA 无需理解,只需要按规定使用即可)的值。对于像浏览器这样的HTTP UA,不知道ETag代表什么,不能预测它的值是多少。如果资源请求的响应头里含有ETag, 客户端可以在后续的请求的头中带上 If-None-Match头来验证缓存。
Last-Modified 响应头可以作为一种弱校验器。说它弱是因为它只能精确到一秒。如果响应头里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。
当向服务端发起缓存校验的请求时,服务端会返回 200ok表示返回正常的结果或者 304Not Modified(不返回body)表示浏览器可以使用本地缓存文件。304的响应头也可以同时更新缓存文档的过期时间。
Vary 响应
Vary HTTP 响应头决定了对于后续的请求头,如何判断是请求一个新的资源还是使用缓存的文件。
当缓存服务器收到一个请求,只有当前的请求和原始(缓存)的请求头跟缓存的响应头里的Vary都匹配,才能使用缓存的响应。

使用vary头有利于内容服务的动态多样性。例如,使用Vary: User-Agent头,缓存服务器需要通过UA判断是否使用缓存的页面。如果需要区分移动端和桌面端的展示内容,利用这种方式就能避免在不同的终端展示错误的布局。另外,它可以帮助 Google 或者其他搜索引擎更好地发现页面的移动版本,并且告诉搜索引擎没有引入Cloaking。
1 | Vary: User-Agent |
因为移动版和桌面的客户端的请求头中的User-Agent不同, 缓存服务器不会错误地把移动端的内容输出到桌面端到用户。
强制缓存和协商缓存的区别
浏览器缓存(Brower Caching)是浏览器对之前请求过的文件进行缓存,以便下一次访问时重复使用,节省带宽,提高访问速度,降低服务器压力。
http缓存机制主要在http响应头中设定,响应头中相关字段为Expires、Cache-Control、Last-Modified、Etag。
浏览器是如何判断是否使用缓存的
第一次请求:
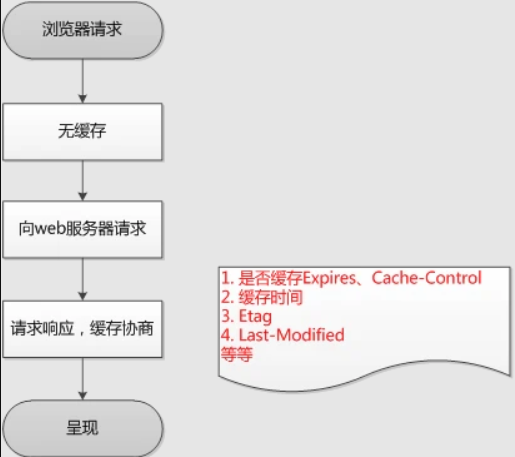
在第一次请求时,没有缓存,直接向服务器发送请求,服务器会将页面最后修改时间通过Last-Modified标识由服务器发送给客户端,客户端记录修改时间;服务器还会生成一个Etag,并发送给客户端。
第二次请求相同网页:
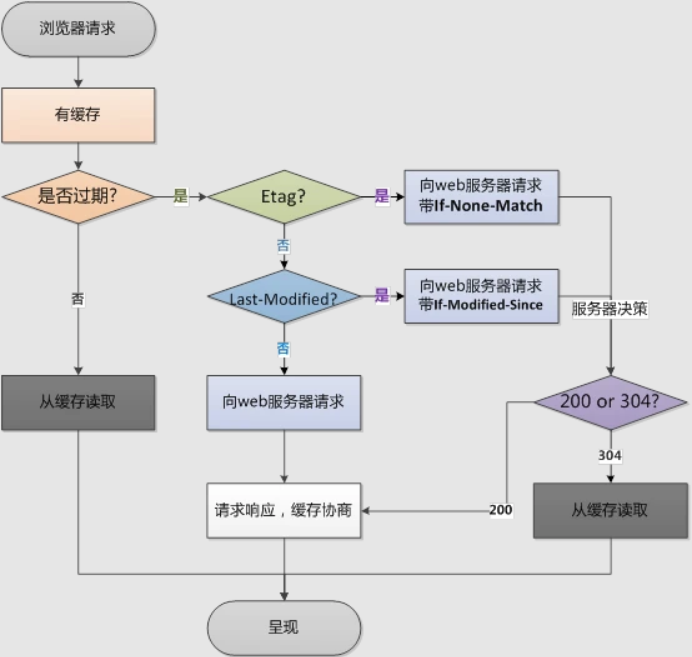
浏览器缓存主要分为强缓存(也称本地缓存)和协商缓存(也称弱缓存)。根据上图,浏览器在第一次请求发生后,再次发送请求时:
浏览器请求某一资源时,会先获取该资源缓存的header信息,然后根据header中的
Cache-Control和Expires来判断是否过期。若没过期则直接从缓存中获取资源信息,包括缓存的header的信息,所以此次请求不会与服务器进行通信。这里判断是否过期,则是强缓存相关。如果显示已过期,浏览器会向服务器端发送请求,这个请求会携带第一次请求返回的有关缓存的header字段信息
- 比如客户端会通过
If-None-Match头将先前服务器端发送过来的Etag发送给服务器,服务会对比这个客户端发过来的Etag是否与服务器的相同- 若相同,就将
If-None-Match的值设为false,返回状态304,客户端继续使用本地缓存,不解析服务器端发回来的数据 - 若不相同就将
If-None-Match的值设为true,返回状态为200,客户端重新解析服务器端返回的数据
- 若相同,就将
- 如果没有
Etag,客户端还会通过If-Modified-Since头将先前服务器端发过来的最后修改时间戳发送给服务器,服务器端通过这个时间戳判断客户端的页面是否是最新的,如果不是最新的,则返回最新的内容,如果是最新的,则返回304,客户端继续使用本地缓存。
- 比如客户端会通过
强缓存
强缓存是利用http头中的Expires和Cache-Control两个字段来控制的,用来表示资源的缓存时间。
强缓存中,普通刷新不会清除它,需要强制刷新。
浏览器强制刷新,请求会带上Cache-Control:no-cache和Pragma:no-cache。
Expires
Expires是http1.0的规范,它的值是一个绝对时间的GMT格式的时间字符串。如我现在这个网页的Expires值是:expires:Fri, 14 Apr 2017 10:47:02 GMT。这个时间代表这这个资源的失效时间,只要发送请求时间是在Expires之前,那么本地缓存始终有效,则在缓存中读取数据。所以这种方式有一个明显的缺点,由于失效的时间是一个绝对时间,所以当服务器与客户端时间偏差较大时,就会导致缓存混乱。如果同时出现Cache-Control:max-age和Expires,那么max-age优先级更高。如我主页的response headers部分如下:
1 | cache-control:max-age=691200 |
那么表示资源可以被缓存的最长时间为691200秒,会优先考虑max-age。
Cache-Control
Cache-Control是在http1.1中出现的,主要是利用该字段的max-age值来进行判断,它是一个相对时间,例如Cache-Control:max-age=3600,代表着资源的有效期是3600秒。cache-control除了该字段外,还有下面几个比较常用的设置值:
no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。no-store:直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
Cache-Control与Expires可以在服务端配置同时启用,同时启用的时候Cache-Control优先级高。
协商缓存
协商缓存就是由服务器来确定缓存资源是否可用,所以客户端与服务器端要通过某种标识来进行通信,从而让服务器判断请求资源是否可以缓存访问。
这个主要涉及到两组header字段:Etag和If-None-Match、Last-Modified和If-Modified-Since。
Etag/If-None-Match
Etag/If-None-Match返回的是一个校验码。ETag可以保证每一个资源是唯一的,资源变化都会导致ETag变化。服务器根据浏览器上送的If-None-Match值来判断是否命中缓存。
与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。
Last-Modify/If-Modify-Since
浏览器第一次请求一个资源的时候,服务器返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间,例如Last-Modify: Thu,31 Dec 2037 23:59:59 GMT。
当浏览器再次请求该资源时,request的请求头中会包含If-Modify-Since,该值为缓存之前返回的Last-Modify。服务器收到If-Modify-Since后,根据资源的最后修改时间判断是否命中缓存。
如果命中缓存,则返回304,并且不会返回资源内容,并且不会返回Last-Modify。
为什么要有Etag
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
- 一些文件也许会周期性的更改,但是他的**内容并不改变(仅仅改变的修改时间)**,这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
- 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
- 某些服务器不能精确的得到文件的最后修改时间。
Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag。
不同刷新的请求执行过程
浏览器地址栏中写入URL,回车 / 普通刷新F5
不同浏览器和不同类型资源缓存方式不同,个人理解:
- 返回200,并显示从缓存中获取,则为强缓存(虽然没有发出真实的 http 请求)。
- 返回304,说明是协商缓存命中走缓存。
强制刷新Ctrl+F5 删除缓存,重新请求。
总结
强缓存有缺点,比如说,设置了expires,GMT格式,但是浏览器的时间可以改变,因此就通过cache-control返回一个相对时间来。但是假如说资源并没有更新,但是强缓存时间过期了,那就需要重新拉去资源,因此就有了Last-Modify,但是last-modified的时间单位是s,当1s内有资源修改,那浏览器返回的最后修改时间和上次的修改时间相同,那就不会重新拉取资源,因此推出了Etag,通过比对资源内容来判断是否修改。
 微信
微信 支付宝
支付宝





